Bidirectional LSTM for summarization
A bidirectional encoder-decoder LSTM neural network is trained for text summarization on the cnn/dailymail dataset.
-The version (only cnn articles and summaries) used in this project can be found here
1) Word embeddings
Word2vec algorithm skipgram is used for the encoder input sequence. This is achieved by training a shallow neural network to ro predict context words given a current word. after training the hidden layer is used as the embedding layer. embedding size was kept at 128. skipgram was pre-trained on both the articles and golden summary words.
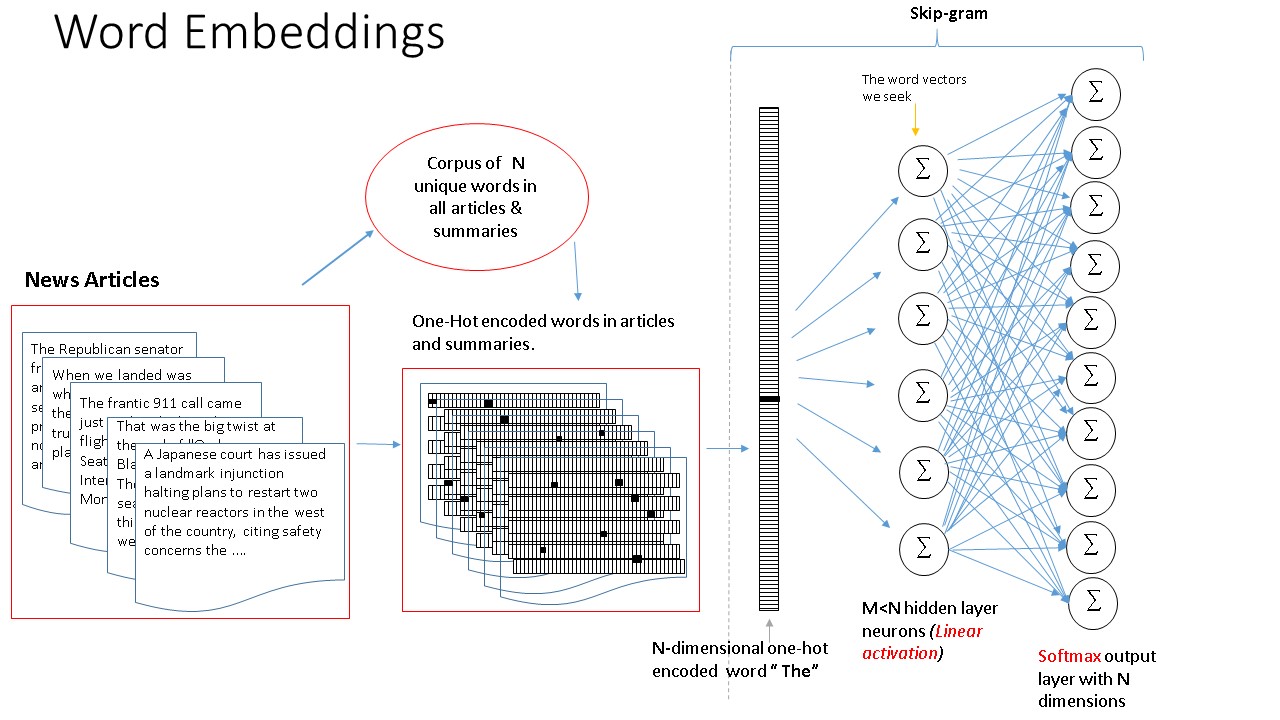
For the decoder input and output, one hot encoding of the summary words was used. vocabulary size was initialy 50k but reduced to 30k due to memory constraints. one hot encoding was also to allow addition of attention layer later.
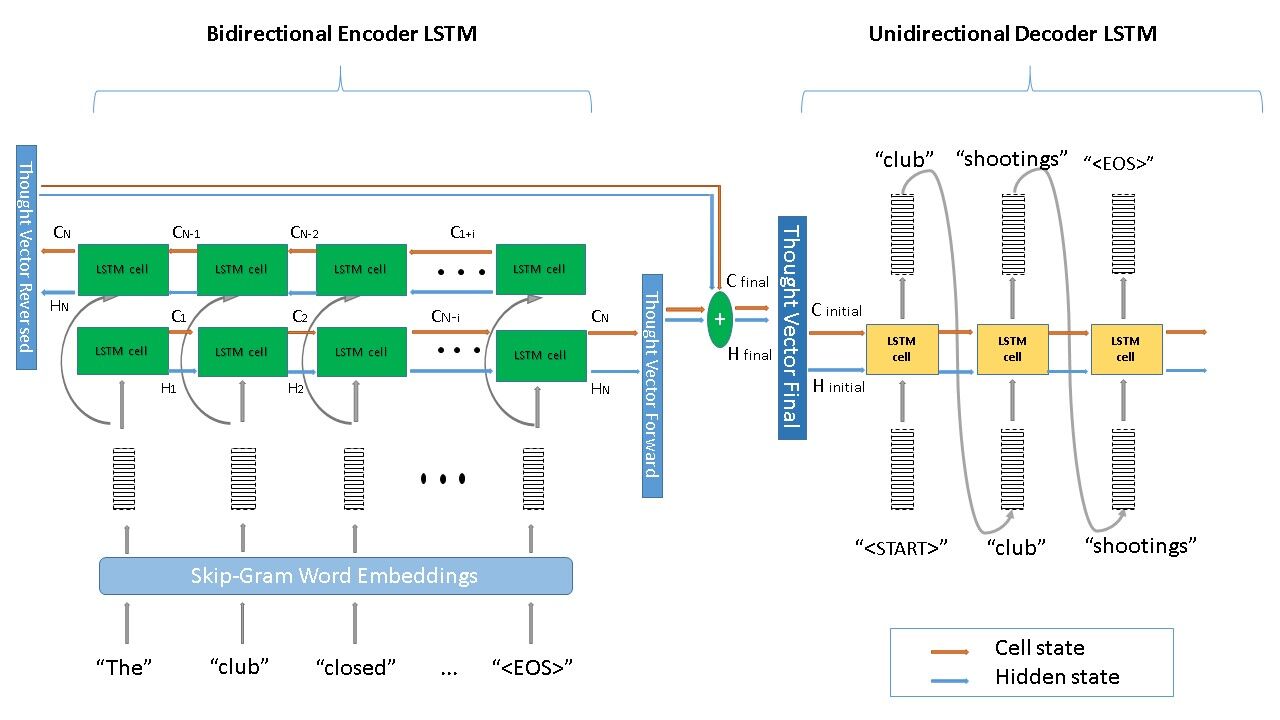
2) Encoder - decoder LSTM
We use a bidirectional encoder lstm with state size = 128, dropout=0.2 and a tanh activation.
The Decoder is a unidirectional lstm with size = 128, droput = 0.2 and a softmax ativation.
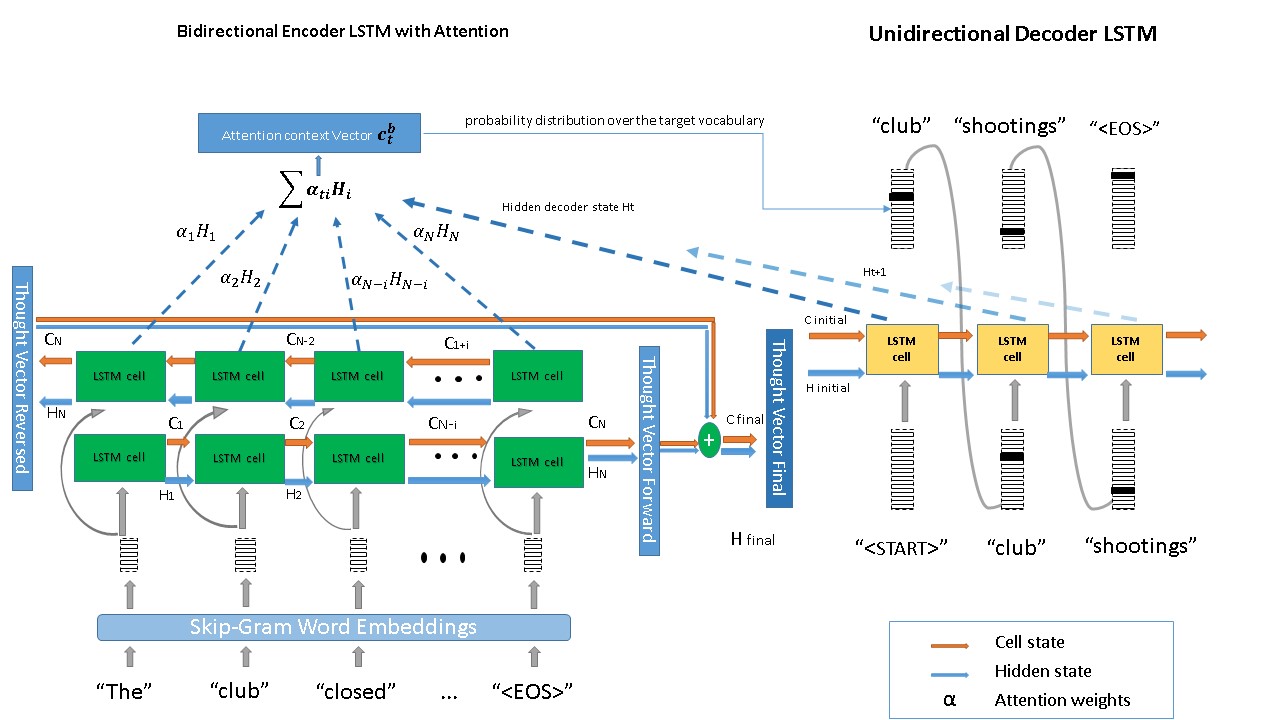
3) Attention Layer
An attention layer between the encoder and decoder over the source sequence’s hidden states. as the skipgram embedding and the one-hot vector sizes arent the same, pca over embedding to allow multiplication with one-hot vectors to get attention weights and vectors. final prediction of output word in decoder sequence is done by the attention layer. It helps allow the decoder individual encoder state information. (forgive the figure below if unclear or messy)
4) Training
Download the data and run the following scripts in this order:
python cnn_daily_load.pypython word2vec.pypython lstm_Attention.py
dependencies
- tensorflow, keras,sklearn
- numpy, pandas, pyrouge, matplotlib
- regex(re), NLTK, gensim
LSTM encoder decoder architectural and trainig parameters:
- batch_size = 50
- epochs = 20
- hidden_units = 128
- learning_rate = 0.005
- clip_norm = 2.0
- test_size = 0.2
- optimizer = RMsprop
- dropout = 0.2 (both encoder and decoder during training)
5) Results
The generated summaries are readable and xmake sense, however they contain repetitions and sometimes skip over important facts or get the plot wrong altogether.
References
- Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate
- Zixiang Ding, Rui Xia, Jianfei Yu, Xiang Li and Jian Yang. Densely Connected Bidirectional LSTM with Applications to Sentence Classification